Columnar File Format과 Storage Access Layer: Apache Parquet와 OpenDAL 기술 분석
이 글은 제가 2025년 5월 18일에 진행한 “Databend 세미나: Topics in Apache Parquet and OpenDAL” 세미나 내용을 기반으로 작성되었습니다.
Apache Parquet
Apache Parquet는 효율적인 데이터 관리와 검색을 위한 오픈소스 열기반 데이터 파일 포맷입니다 [1]. Hadoop ecosystem에 최적화된 열기반 데이터 표현을 제공하기 위해 시작되었습니다. Parquet의 대표적인 특징으로는 열기반 스토리지, 압축, 최적화된 쿼리 프로세싱이 있습니다.
열기반 스토리지
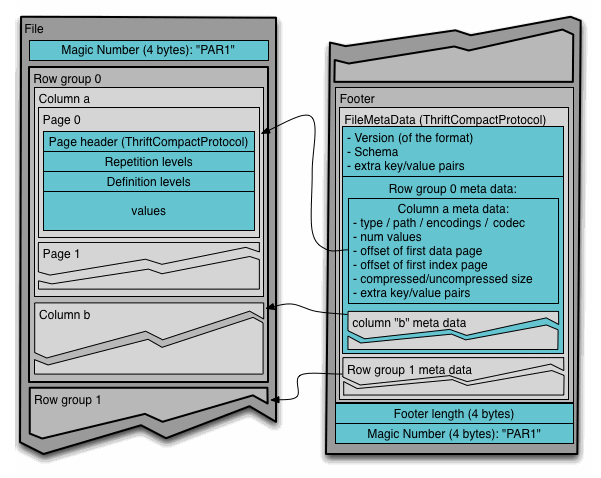
Parquet 파일의 내부 구조 [1]
위 그림은 Parquet 파일 하나의 구성을 나타냅니다. 하나의 Parquet 파일은 하나의 테이블 데이터를 담습니다. 파일에는 데이터 영역과 메타데이터 영역이 있습니다. 데이터 영역은 연속된 row group으로 이루어져 있고, 각각의 row group에는 특정 개수 만큼의 레코드(튜플) 데이터가 column chunk로 구분되어 저장되어 있습니다. 하나의 column chunk는 하나의 열(column)에 해당하고, 이것은 여러 개의 페이지로 구성되어 있습니다. 각각의 페이지는 페이지의 정보를 나타내는 페이지 헤더(메타데이터)와 nested 데이터(e.g., JSON, Protobuf, etc.)를 관리하기 위한 repetition levels 및 definition levels (이에 대해서는 이후에 다룹니다), 그리고 실제 데이터를 관리합니다.
메타데이터는 Thrift Protocol [2]로 정의되어 있습니다. 파일의 가장 끝부분에 위치한 파일 메타데이터는 스키마 정보, 각 row group의 정보 (데이터의 위치, 압축 방식 등) 등을 저장합니다.
이런 식으로 데이터를 row group과 column chunk로 나누어 저장하는 방식을 PAX(Partition Attributes Across)라고 합니다. DuckDB의 storage format도 유사한 방식으로 구성되어 있습니다 [6].
최적화된 쿼리 프로세싱 및 압축
Parquet는 predicate pushdown 기능을 지원하여 빠른 스캔 성능을 제공하고, 효율적인 압축을 통해 저장 공간을 최적화합니다. 이러한 기능을 위해 Parquet는 zone map (min/max 통계), dictionary encoding (+ run-length encoding과 bit packing), bloom filter, 그리고 다양한 압축 알고리즘을 사용합니다.
Zone map
Parquet는 각각의 row group 내에 있는 column chunk마다 데이터의 min 값과 max 값을 통계 정보로 기록해 두고 있습니다. 이를 zone map이라고 합니다. Zone map이 있다면, Parquet 파일에 대해 스캔을 수행할 때, 관련 없는 column chunk에 대한 스캔을 생략할 수 있습니다.
예를 들어 ORDER BY created_date로 정렬된 주문 데이터가 있다고 가정해보겠습니다. Row Group A는 created_date의 min=2025-01-01, max=2025-01-31을, Row Group B는 min=2025-02-01, max=2025-02-28을 zone map으로 가지고 있다면, WHERE created_date >= '2025-02-15'라는 쿼리 실행 시 Row Group A는 스캔하지 않고 건너뛸 수 있습니다.
데이터의 정렬 상태에 따라 zone map의 효과는 매우 클 수 있고, 반대로 매우 작을 수도 있습니다. 만약 데이터가 특정 열을 기준으로 정렬되어 있다면 zone map의 효과는 매우 클 것입니다. 반면 데이터가 정렬되어 있지 않으면서 skewed 되어 있다면, zone map의 효과는 미미할 수 있습니다.
Dictionary encoding
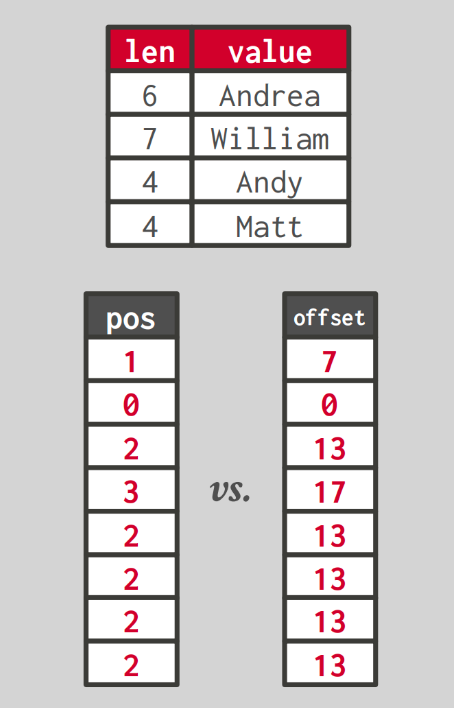
Dictionary encoding 예시 [3]
Dictionary encoding은 데이터에서 자주 나타나는 값을 dictionary에 저장하고, 데이터는 좀 더 작은 code(예를들어 정수값)로 표현하는 방법입니다. 이 방법은 데이터 압축 측면에서도 좋고, 문자열과 같이 크기가 큰 데이터에 대한 query processing 할 때 유용합니다. 전체 문자열에 대해 연산을 수행할 필요 없이, code를 이용하여 연산을 수행할 수 있기 때문입니다. 물론 원본 값이 필요할 때에는 그 code에 해당하는 값을 dictionary를 통해 되찾습니다.
대체로 두가지 방식의 code가 사용됩니다. 하나는 dictionary에 각 데이터 값과 이에 대한 길이를 저장하고, 원본 데이터가 dictionary 내에서 몇번째 index에 저장되어 있는지를 code로 사용하는 방법입니다. 다른 하나는 dictionary에 데이터 값을 연속된 위치에 저장하고, dictionary 내에서 원본 데이터가 몇번째 offset에 저장되어 있는지를 code로 사용하는 방법입니다. 위 그림은 dictionary encoding을 이용하여 문자열을 저장할 때의 이득을 보여주는 예시입니다. 위쪽에는 dictionary가 있고, 왼쪽 아래에는 첫번째 방식의 code, 오른쪽 아래에는 두번째 방식의 code를 이용하여 encoding 한 결과를 보여줍니다. 문자열을 그대로 데이터로 저장한다면 많은 공간을 차지할 수 있지만, 그림과 같이 인코딩하여 관리하면 더 적은 공간으로 처리할 수 있습니다.
Parquet는 run-length encoding과 bitpacking encoding을 dictionary encoding와 함께 사용합니다. 이를 통해 데이터를 추가적으로 압축하여 더욱 효율적인 저장 공간을 확보할 수 있습니다. Run-length encoding은 반복된 값이 포함된 데이터를 값과 중복된 횟수의 쌍으로 변환합니다. 예를 들어 [1,1,2,2,2,2,3,3]과 같은 데이터가 있을 때 run-length encoding의 결과는 [(1,2),(2,4),(3,2)]가 됩니다.
다른 인코딩 방법 중 하나인 bitpacking encoding은 데이터를 저장할 때 필요한 최소한의 비트만을 사용하여 저장하는 인코딩 방식입니다. 우리가 데이터를 32비트 integer로 표현한다고 할 때, 항상 32비트를 꽉 채워서 사용하는 것은 아닙니다. 만약 우리가 이 데이터의 범위를 알고 있다면(e.g., 페이지 내의 int32 타입 데이터가 0-1000 범위를 가진다면), 우리는 이 정보를 바탕으로 사용하는 비트의 수를 줄일 수 있습니다(e.g., 2¹⁰=1024로 충분히 커버가 가능하므로 10비트+α 로 표현 가능).
Run-length encoding과 bitpacking encoding은 dictionary encoding 없이 데이터에 대해 단독으로 적용될 수도 있습니다.
Parquet는 low cardinality(i.e., distinct한 값의 개수가 적은 경우) 상황일 때 dictionary encoding을 사용합니다. 하나의 열에 같은 값이 많은 경우가 이에 해당하는데, 이 때는 dictionary encoding이 효과적일 것입니다.
Bloom filter
위에서 살펴본 zone map이나 dictionary encoding이 효과가 없는 경우가 있을 수 있습니다. 데이터가 large cardinality를 가지면서 매우 skewed 되어 있을 수 있습니다. 그렇다면 이런 경우에는 빠른 스캔을 어떻게 만들어 낼 수 있을까요?
Parquet는 이러한 경우 bloom filter [8]를 사용합니다. Bloom filter는 특정 원소가 집합에 포함되어 있는지 여부를 확률적으로 판단하는 자료구조입니다. 이것이 “No”를 반환한다면 데이터가 확실히 없는 것이고, “Yes”를 반환한다면 데이터가 있을 수도 있고, 없을 수도 있습니다(False Positive). Bloom filter는 적은 양의 메모리(데이터 개수 N보다 작은 bits)를 이용하여 “Yes” 혹은 “No” 질의를 빠르게 처리할 수 있습니다. 데이터 저장 시 Parquet는 bloom filter를 만들고, 우리가 데이터를 찾을 때 이 bloom filter를 사용합니다. 만약에 bloom filter가 “Yes”를 반환한다면 해당 column chunk를 스캔해 보는 것이고, “No”를 반환한다면 해당 데이터를 건너뜁니다.
압축
더 나은 공간 효율성을 위해 Parquet는 다양한 압축 알고리즘을 지원합니다. 대표적으로 gzip, snappy, zstd 등이 있으며, 각각은 압축률과 성능 간의 서로 다른 trade-off를 제공합니다. Gzip은 높은 압축률을 제공하지만 상대적으로 느리고, Snappy는 낮은 압축률을 가지지만 빠른 압축/해제 속도를 제공합니다. Zstd는 두 방식의 중간 지점으로 양호한 압축률과 성능을 모두 제공합니다. 압축은 page 단위로 적용되며, 앞서 언급한 dictionary encoding이나 run-length encoding과 함께 사용되어 더욱 효과적인 압축을 달성할 수 있습니다.
Nested Data
Parquet는 설계 단계에서부터 nested 데이터를 고려하였습니다 [1]. Nested 데이터를 저장 및 관리하기 위해 Dremel(Google BigQuery) [9][10]에서 사용한 방법을 채택하였습니다.
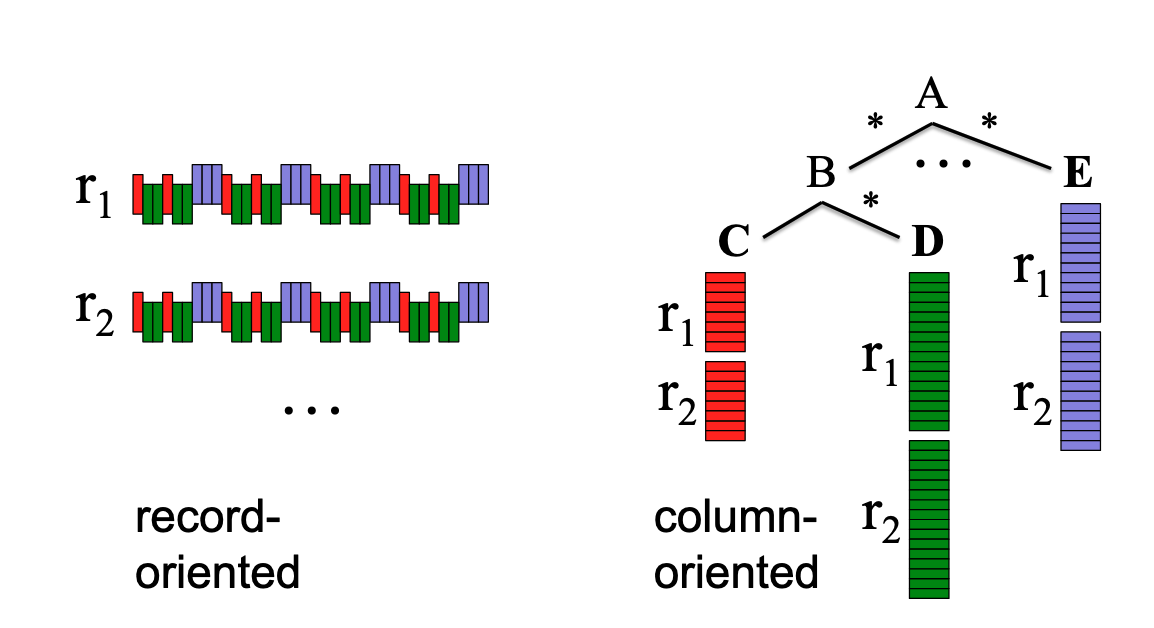
Dremel의 nested 데이터 관리 개념 [9]
위 그림은 Dremel이 nested 데이터를 관리하는 방법을 개념적으로 나타낸 것입니다. 우측의 트리 구조와 같이 A라는 객체 안에 B, …, E 라는 반복 혹은 생략 가능한 객체가 존재하고, B라는 객체 안에는 C라는 객체와 D라는 반복 혹은 생략 가능한 객체가 존재합니다 (JSON이나 Protobuf와 같은 형태를 생각해 보세요).
이런 객체를 관리하고자 할 때 우리가 데이터를 생긴 그대로 저장한다면, 그림의 좌측과 같이 각각의 nested 객체에 대한 정보가 뒤섞여서 저장되게 됩니다. 반면 Dremel은 열기반 데이터 포맷을 활용하여 우측과 같이 각각의 path에 해당하는 데이터를 연속된 공간에 저장하는 것을 제안했습니다. 후자의 경우 분석 질의를 처리하는 관점에서 더 이득이 있을 것입니다.
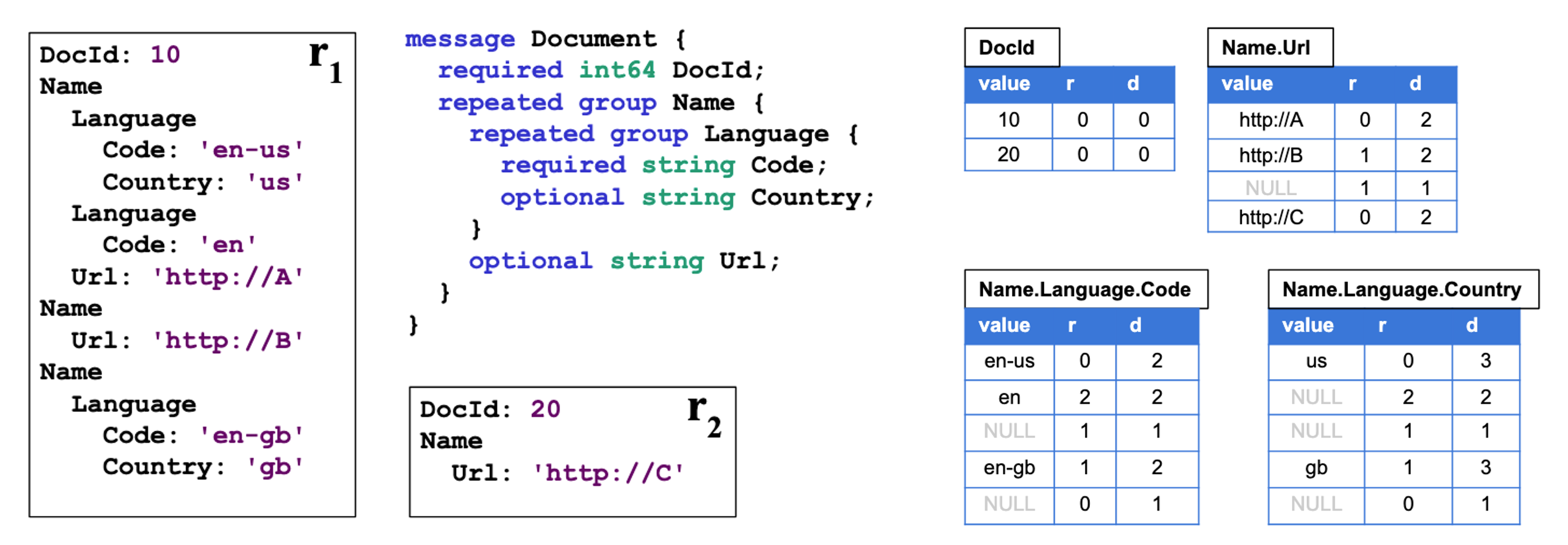
Dremel의 구체적인 nested 데이터 관리 방법 [10]
위 그림은 구체적으로 데이터를 어떻게 관리하는지 나타냅니다. 그림의 좌측에는 protobuf의 스키마와 예시 레코드 r₁과 r₂가 있습니다. Dremel은 스키마의 각각의 path 별로 그림 우측과 같이 분리된 테이블을 생성합니다.
이 테이블에는 해당 필드에 대한 값(value), repetition level 그리고 definition level을 함께 기록해 둡니다. Repetition level은 현재 튜플과 이전 튜플을 비교했을 때 path 중 어느 depth에서 필드의 반복이 발생하였는지 기록하고 있고, definition level은 현재 튜플이 정의된 path 중 몇개의 optional 필드가 실제로는 정의되었는지 기록하고 있습니다.
Dremel은 nested object를 저장할 때 위와 같은 방식으로 path를 쪼개고 value, repetition level, definition level을 기록합니다. 또한 데이터를 처리해야 하는 시점에는 이 정보들을 활용하여 원본 데이터가 어떻게 생겼는지를 파악하고 데이터를 처리합니다.
더 생각해 볼 주제
- 열 기반의 데이터 포맷으로 Apache ORC도 많이 사용되는데, Apache ORC와 Parquet의 차이점은?
- Bloom filter는 range query에도 활용될 수 있을까?
Apache OpenDAL
OpenDAL은 다양한 스토리지 서비스와 seamless하게 소통할 수 있는 데이터 접근 레이어 입니다. One layer, all storage를 표방하고 있습니다.
Components
OpenDAL에는 Service, Layer, 그리고 Operator 컴포넌트가 있습니다.
-
Service는 storage backend를 지정하는 컴포넌트입니다. AWS S3나 Azure Blob(Azblob)과 같이 bucket service 뿐 아니라 POSIX file system(Fs), PostgreSQL이나 MongoDB 등의 database 접근을 위한 서비스를 제공합니다 [5].
-
Layer는 데이터를 접근할 때 사용할 수 있는 부가적인 기능을 제공합니다. 데이터에 대한 연산 수행 시 logging을 해주는
LoggingLayer나 연산 실패 시 자동으로 retry를 수행해주는RetryLayer, timeout을 설정해주는TimeoutLayer등을 제공합니다 [7]. -
Operator는 Service에서 지정된 storage에 접근할 수 있도록 합니다. Read, write, stat, delete, create_dir, copy 등의 연산을 제공합니다. 우리는 이를 통해 데이터를 생성하거나 수정, 삭제할 수 있습니다.
OpenDAL은 현재 특정 범위의 데이터를 읽는 read_with() 함수는 지원하나, 특정 위치에 데이터를 쓰는 기능(e.g., pwrite() in POSIX)는 지원하지 않습니다.
DataBend와의 관계
DataBend는 Fuse Engine을 스토리지 엔진으로 사용하며, OpenDAL을 데이터 접근 레이어(data access layer)로 사용합니다. 즉, Fuse Engine은 데이터의 포맷이나 연산을 총괄하는 주체이고, OpenDAL은 그 중에서 데이터를 읽고 쓰는 기능에 집중한다고 할 수 있습니다.
Fuse Engine
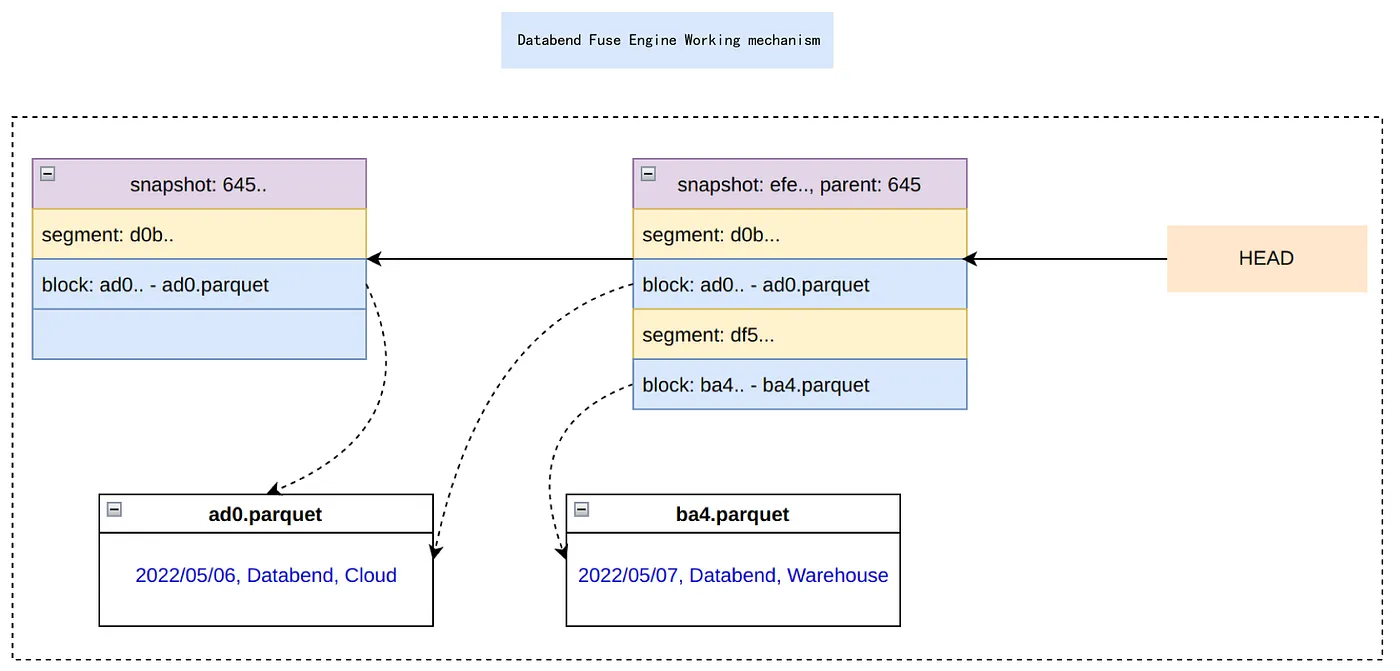
Fuse Engine의 테이블 관리 메커니즘 [4]
위 그림은 Fuse Engine이 하나의 테이블을 관리하는 메커니즘을 표현합니다. Fuse Engine은 하나의 테이블을 3가지 요소를 통해 관리합니다.
- Block: 실제 데이터 조각입니다. Parquet 파일로 구성되어 있습니다.
- Segment: Block들과 이것들의 메타데이터 입니다. 예를 들어 몇 개의 행을 가지고 있는지, 데이터의 사이즈가 어느 정도인지 등을 나타냅니다.
- Snapshot: 특정 시점의 테이블의 상태를 나타내며, Segment들을 포함합니다.
테이블이 업데이트(레코드 삽입, 삭제, 수정)될 때마다 새로운 Snapshot이 만들어집니다. 만약 데이터를 포함하는 Block이 변경되어야 한다면 Fuse Engine은 새로운 Block을 만들어 내고 이를 포함하는 새로운 Segment와 Snapshot을 만듭니다. 변경되지 않은 Segment나 Block은 테이블이 업데이트 되더라도 새로 만들어지지 않고 기존의 것을 재사용합니다.
Apache Iceberg도 이와 유사한 방식으로 table을 관리합니다.
더 생각해 볼 주제
- 기존의 RDBMS는 데이터가 업데이트될 때 무슨 일이 일어날까? (PostgreSQL과 MySQL을 위주로 살펴보기)
- Concurrency control과 performance 측면에서 기존의 RDBMS 방식들과 DataBend의 방식은 어떤 장단점이 있을까?
참고문헌
[1] The Apache Software Foundation. Apache Parquet. 2025. https://parquet.apache.org/
[2] The Apache Software Foundation. Apache Thrift. 2025. https://thrift.apache.org/
[3] Andy Pavlo. Lecture #02: Data Formats & Encoding I. 2024. https://15721.courses.cs.cmu.edu/spring2024/notes/02-data1.pdf
[4] DataBend. From Git to Fuse Engine. 2022. https://medium.com/@databend/from-git-to-fuse-engine-c824b9adea6f
[5] OpenDAL. Module services. 2025. https://docs.rs/opendal/latest/opendal/services/index.html
[6] Mark Raasveldt. Lightweight Compression in DuckDB. 2022. https://duckdb.org/2022/10/28/lightweight-compression.html
[7] OpenDAL. Module layers. 2025. https://docs.rs/opendal/latest/opendal/layers/index.html
[8] Burton H. Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7):422–426, July 1970.
[9] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis. Dremel: Interactive Analysis of Web-Scale Datasets. Proc. of the 36th Int’l Conf on Very Large Data Bases, pages 330-339, 2010.
[10] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, and others. Dremel: A decade of interactive SQL analysis at web scale. Proceedings of the VLDB Endowment, 13(12):3461–3472, 2020.