Columnar File Format and Storage Access Layer: Technical Analysis of Apache Parquet and OpenDAL
This post is a translated version of the blog post originally written in Korean. This article is based on my seminar “Databend Seminar: Topics in Apache Parquet and OpenDAL” presented on May 18, 2025.
Apache Parquet
Apache Parquet is an open-source column-oriented data file format for efficient data management and retrieval [1]. It was started to provide column-oriented data representation optimized for the Hadoop ecosystem. Parquet’s key characteristics include column-oriented storage, compression, and optimized query processing.
Column-Oriented Storage
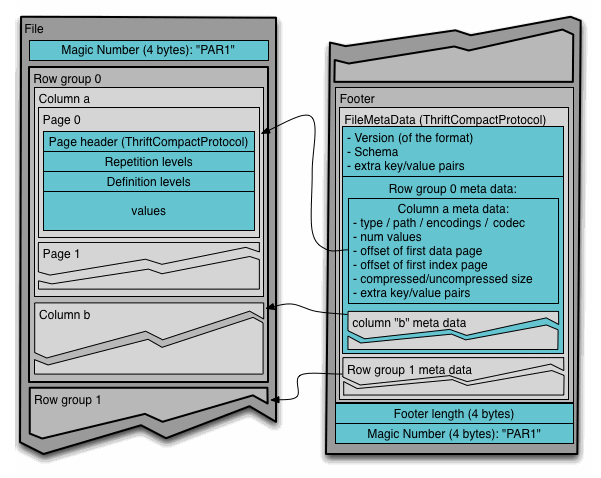
Internal Structure of a Parquet File [1]
The above diagram shows the structure of a single Parquet file. One Parquet file contains one table’s data. The file has a data area and metadata areas. The data area consists of consecutive row groups, and each row group contains data for a specific number of records (tuples) stored as column chunks. One column chunk corresponds to one column, and it consists of multiple pages. Each page contains a page header (metadata) that includes page information, repetition and definition levels for managing nested data (e.g., JSON, Protobuf, etc.) (we’ll cover this later), and the actual data. The metadata located at the end of the file stores schema information and details about each row group like data location and compression method. The metadata is defined using Thrift Protocol [2].
This method of storing data divided into row groups and column chunks is called PAX (Partition Attributes Across). DuckDB’s storage format is also structured in a similar way [6].
Optimized Query Processing and Compression
Parquet supports predicate pushdown functionality for fast scan performance and optimizes storage space through efficient compression. For these functionalities, Parquet uses zone maps (min/max statistics), dictionary encoding (+ run-length encoding and bit packing), bloom filters, and various compression algorithms.
Zone Map
Parquet records the minimum and maximum values of data as statistical information for each column chunk within each row group. This is called a zone map. With zone maps, when performing scans on Parquet files, scans of unrelated row groups can be skipped.
For example, suppose we have order data sorted by ORDER BY created_date. If Row Group A has min=2025-01-01, max=2025-01-31 for created_date, and Row Group B has min=2025-02-01, max=2025-02-28 in its zone map, then when executing a query like WHERE created_date >= '2025-02-15', Row Group A can be skipped without scanning.
Depending on the sorting state of data, the effectiveness of zone maps can be very large or very small. If data is sorted based on a specific column, the zone map’s effectiveness will be very large. Conversely, if data is unsorted and skewed, the zone map’s effectiveness may be minimal.
Dictionary Encoding
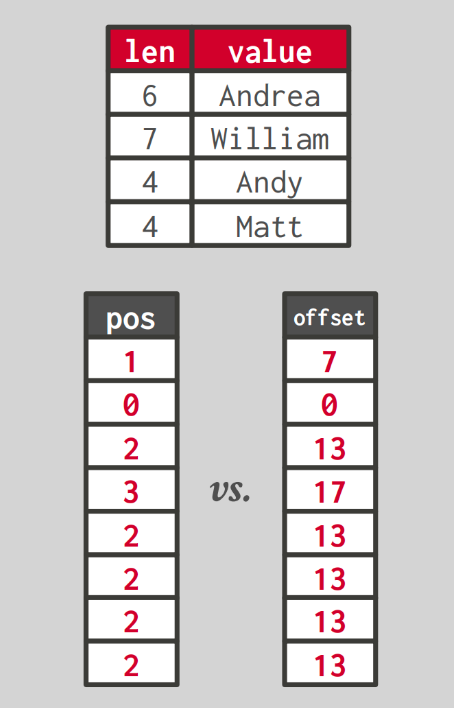
Dictionary encoding example [3]
Dictionary encoding is a method that stores frequently appearing values in a dictionary and represents data with smaller codes (e.g., integer values). This method is good from a data compression perspective and useful for query processing on large-sized data such as strings. This is because operations can be performed using codes without needing to operate on entire strings. Of course, when the original value is needed, the corresponding value is retrieved through the dictionary using the code.
Generally, two types of codes are used. One method stores each data value and its length in the dictionary, and uses which index the original data is stored at in the dictionary as the code. The other method stores data values in consecutive positions in the dictionary, and uses which offset the original data is stored at within the dictionary as the code. The above diagram shows an example of the benefits when storing strings using dictionary encoding. The top shows the dictionary, the bottom left shows the encoding result using the first method’s code, and the bottom right shows the encoding result using the second method’s code. If strings were stored as data directly, they could take up a lot of space, but by encoding and managing them as shown in the diagram, they can be processed with less space.
Parquet uses run-length encoding and bitpacking encoding together with dictionary encoding. This allows for additional compression of data to achieve even more efficient storage space. Run-length encoding converts data containing repeated values into pairs of values and repetition counts. For example, with data like [1,1,2,2,2,2,3,3], the run-length encoding result would be [(1,2),(2,4),(3,2)].
Another encoding method, bitpacking encoding, uses only the minimum bits needed when storing data. Even though we represent data as 32-bit integers, we don’t always use all 32 bits. If we know the range of this data (e.g., if int32 type data within a page have a range of 0-1000), we can reduce the number of bits used based on this information (e.g., since 2¹⁰=1024 provides sufficient coverage, it can be represented with 10 bits+α).
Run-length encoding and bitpacking encoding can be applied to data independently without dictionary encoding.
Parquet uses dictionary encoding in low cardinality situations. This applies when the same values appear frequently in a column, where dictionary encoding would be effective.
Bloom Filter
There may be cases where the zone maps or dictionary encoding explored above are ineffective. Data might have large cardinality while being very skewed. So how can we create fast scans in such cases?
Parquet uses bloom filters [8] for such cases. A bloom filter is a data structure that probabilistically determines whether a specific element is included in a set. If it returns “No,” the data is definitely not there, and if it returns “Yes,” the data may or may not be there (False Positive). Bloom filters can quickly process “Yes” or “No” queries using a small amount of memory (fewer bits than the number of data items N). When storing data, Parquet creates bloom filters, and when we search for data, these bloom filters are used. If the bloom filter returns “Yes,” we scan the corresponding column chunk; if it returns “No,” we skip that data.
Compression
For better space efficiency, Parquet supports various compression algorithms. These include gzip, snappy, zstd, each providing different trade-offs between compression ratio and performance. Gzip provides high compression ratios but is relatively slow, while Snappy has lower compression ratios but offers fast compression/decompression speeds. Zstd serves as a middle ground, providing both good compression ratios and performance. Compression is applied at the page level, and when combined with the aforementioned dictionary encoding or run-length encoding, it can achieve even more effective compression.
Nested Data
Parquet considered nested data from the design stage [1]. To store and manage nested data, it adopted the method used by Dremel (Google BigQuery) [9][10].
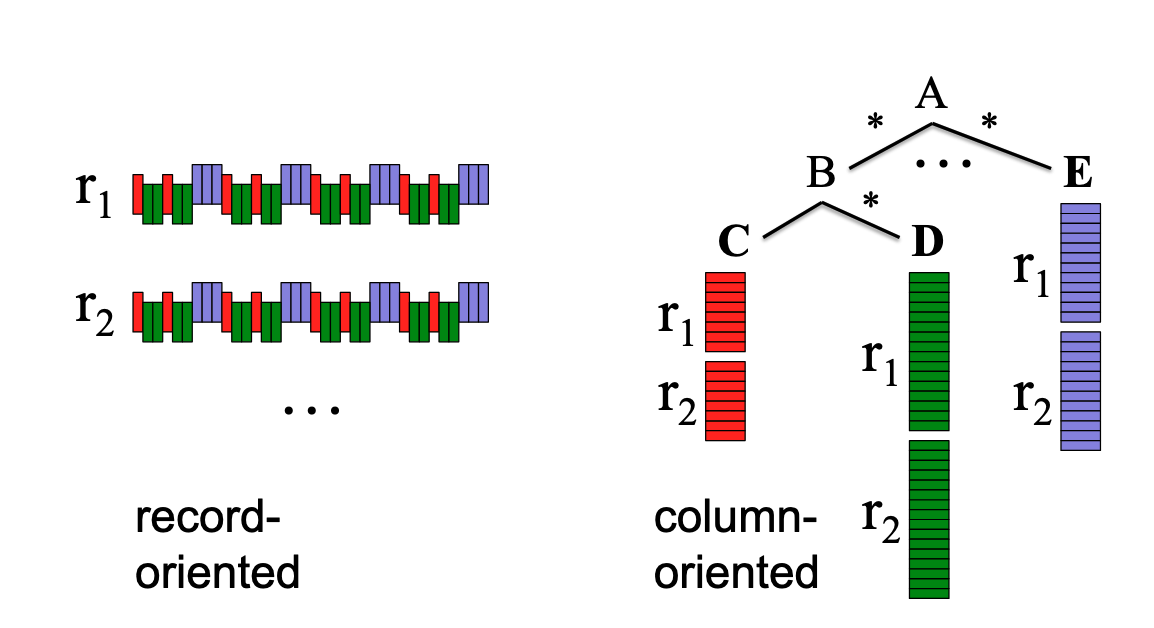
Dremel’s Nested Data Management Concept [9]
The above diagram conceptually shows how Dremel manages nested data. Like the tree structure on the right, object A contains repeatable or optional objects B, …, E, and object B contains object C and repeatable or optional object D (think of formats like JSON or Protobuf).
When managing such objects, if we stored data as it appears, information about each nested object would be mixed and stored as shown on the left side of the diagram. In contrast, Dremel proposed using column-oriented data format to store data corresponding to each path in consecutive space as shown on the right. The latter approach would be more advantageous from the perspective of processing analytical queries.
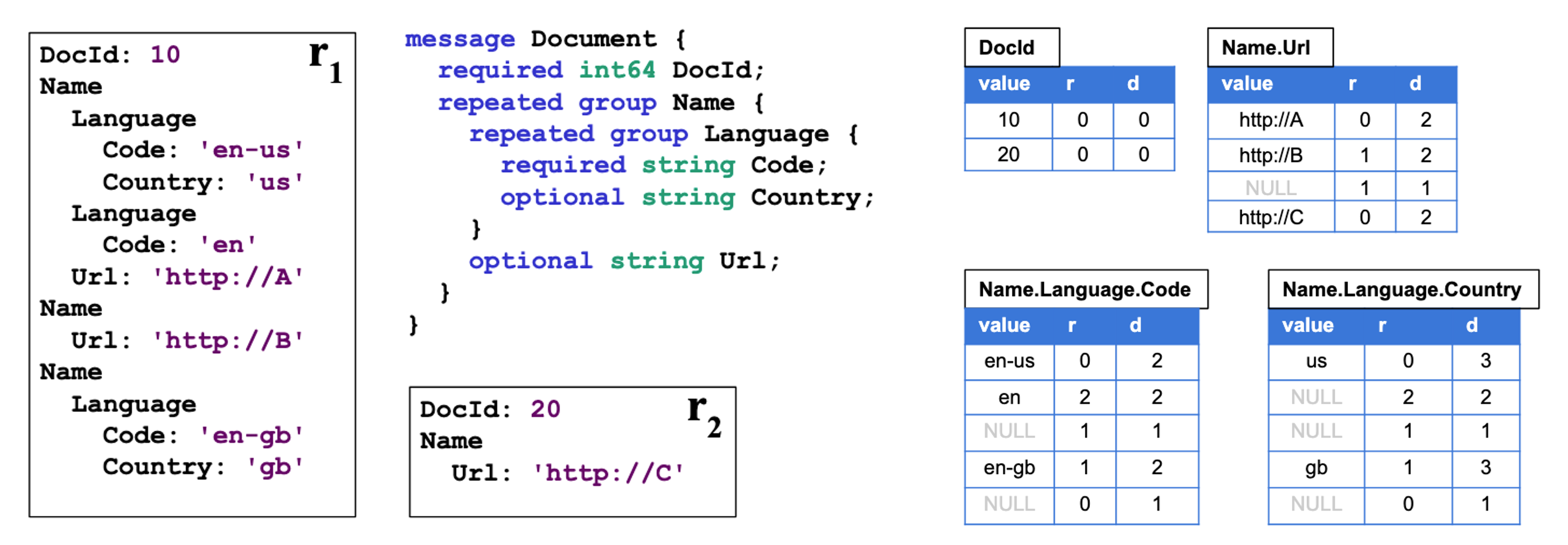
Dremel’s Specific Nested Data Management Method [10]
The above diagram shows specifically how data is managed. On the left side of the diagram are the protobuf schema and example records r₁ and r₂. Dremel creates separate tables for each path in the schema as shown on the right side of the diagram.
These tables record values for the corresponding fields, repetition levels, and definition levels together. Repetition levels record at which depth in the path field repetition occurred when comparing the current tuple with the previous tuple, and definition levels record how many optional fields in the paths were actually defined.
When storing nested objects, Dremel splits paths as described above and records values, repetition levels, and definition levels. When data needs to be processed, it uses this information to understand what the original data looked like and processes the data.
Further Topics to Consider
- Apache ORC is also widely used as a column-oriented data format. What are the differences between Apache ORC and Parquet?
- Can bloom filters also be utilized for range queries?
Apache OpenDAL
OpenDAL is a data access layer that can communicate seamlessly with various storage services. It advocates “One layer, all storage.”
Components
OpenDAL has Service, Layer, and Operator components.
-
Service is a component that specifies storage backends. It provides access to bucket services like AWS S3 and Azure Blob (Azblob), as well as POSIX file systems (Fs) and database access services like PostgreSQL and MongoDB [5].
-
Layer provides additional functionality that can be used when accessing data. It provides
LoggingLayerfor logging during data operations,RetryLayerfor automatic retries on operation failures,TimeoutLayerfor setting timeouts, etc. [7] -
Operator enables access to storage specified in Service. It provides operations like read, write, stat, delete, create_dir, copy. We can create, modify, or delete data through these operations.
OpenDAL currently supports the read_with() function for reading specific ranges of data, but does not support functionality for writing data at specific positions (e.g., pwrite() in POSIX).
Relationship with DataBend
DataBend uses Fuse Engine as its storage engine and OpenDAL as its data access layer. In other words, Fuse Engine is the entity that manages data formats and operations, while OpenDAL focuses on reading and writing data functionality.
Fuse Engine
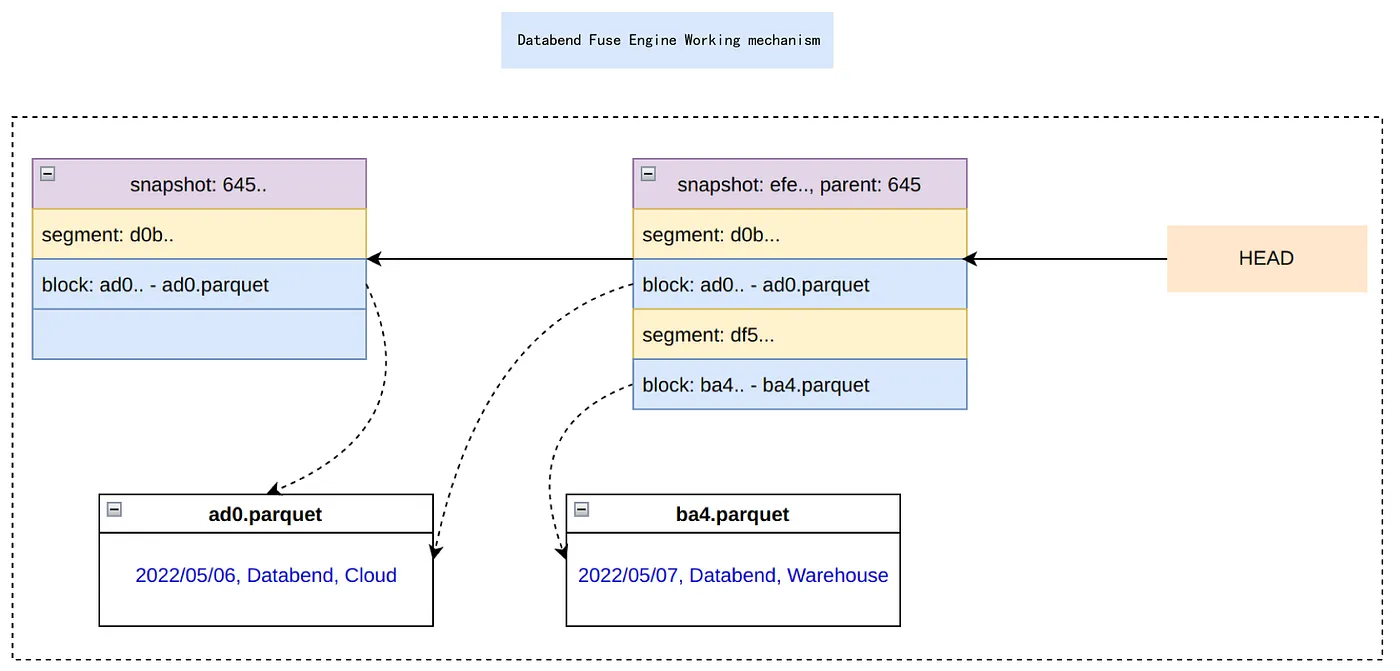
Fuse Engine’s Table Management Mechanism [4]
The above diagram represents the mechanism by which Fuse Engine manages a single table. Fuse Engine manages one table through three elements:
- Block: Actual data fragments. Composed of Parquet files.
- Segment: Blocks and their metadata. For example, it indicates how many rows they contain, what the data size is, etc.
- Snapshot: Represents the state of a table at a specific point in time and contains Segments.
Each time a table is updated (record insertion, deletion, modification), a new Snapshot is created. If a Block containing data needs to be changed, Fuse Engine creates a new Block and makes new Segments and Snapshots containing it. Unchanged Segments or Blocks are not recreated when tables are updated but reuse existing ones.
Apache Iceberg also manages tables in a similar way.
Further Topics to Consider
- What happens when data is updated in existing RDBMS? (Focus on PostgreSQL and MySQL)
- What are the advantages and disadvantages of existing RDBMS approaches versus DataBend’s approach in terms of concurrency control and performance?
References
[1] The Apache Software Foundation. Apache Parquet. 2025. https://parquet.apache.org/
[2] The Apache Software Foundation. Apache Thrift. 2025. https://thrift.apache.org/
[3] Andy Pavlo. Lecture #02: Data Formats & Encoding I. 2024. https://15721.courses.cs.cmu.edu/spring2024/notes/02-data1.pdf
[4] DataBend. From Git to Fuse Engine. 2022. https://medium.com/@databend/from-git-to-fuse-engine-c824b9adea6f
[5] OpenDAL. Module services. 2025. https://docs.rs/opendal/latest/opendal/services/index.html
[6] Mark Raasveldt. Lightweight Compression in DuckDB. 2022. https://duckdb.org/2022/10/28/lightweight-compression.html
[7] OpenDAL. Module layers. 2025. https://docs.rs/opendal/latest/opendal/layers/index.html
[8] Burton H. Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7):422–426, July 1970.
[9] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis. Dremel: Interactive Analysis of Web-Scale Datasets. Proc. of the 36th Int’l Conf on Very Large Data Bases, pages 330-339, 2010.
[10] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, and others. Dremel: A decade of interactive SQL analysis at web scale. Proceedings of the VLDB Endowment, 13(12):3461–3472, 2020.